On Training DeFi Agents with Markov Chains

This work was originally published on April 18th, 2023, by bt3gl.
Reinforcement Learning and Agents
The difference between reinforcement learning and supervised or unsupervised learning is that it uses training information on the agent’s action rather than teaching the correct actions.
At a high-level, the elements of a reinforcement learning system are:
- The agent (the learning bot).
- A model of the environment (anything outside the agent).
- A policy, defining the learning agent's behavior at a given time (think a map of perceived states to actions to be taken). It might be stochastic (defining probabilities for each action).
- A reward signal, modeling the goal of the agent. It's the value given by the environment and sent to the agent on each time step, which needs to be maximized.
- A value function, specifying the total reward the agent can expect to accumulate over the future (and can be used to find better policies).
Therefore, solving a reinforcement learning task means having your agent interact with the environment to find a policy that achieves great reward over the long run (maximizing the value function).
Markov Decision Processes
Markov decision processes (MDP) are a canonical framing of the problem of learning from interaction with an environment to achieve a goal.
The environment's role is to return rewards, i.e., some numerical values that the agent wants to maximize over time through its choices of actions.
Back in Statistical and Quantum Physics, we use Markov chains to model random walks of particles and phase transitions. This is because Markov chains are a classical formalization of sequential decision-making, where actions influence immediate rewards and subsequent situations. This means looking at the trade-offs of delayed reward by evaluating feedback and choosing different actions in different situations.
For our DeFi agent, a reinforcement learning task can be formulated as a markov decision problem by the following process:
- The agent acts in a trading environment, which is a non-stationary pvp game with thousands of agents acting simultaneously. Market conditions change, agents join or leave or constantly change their strategies.
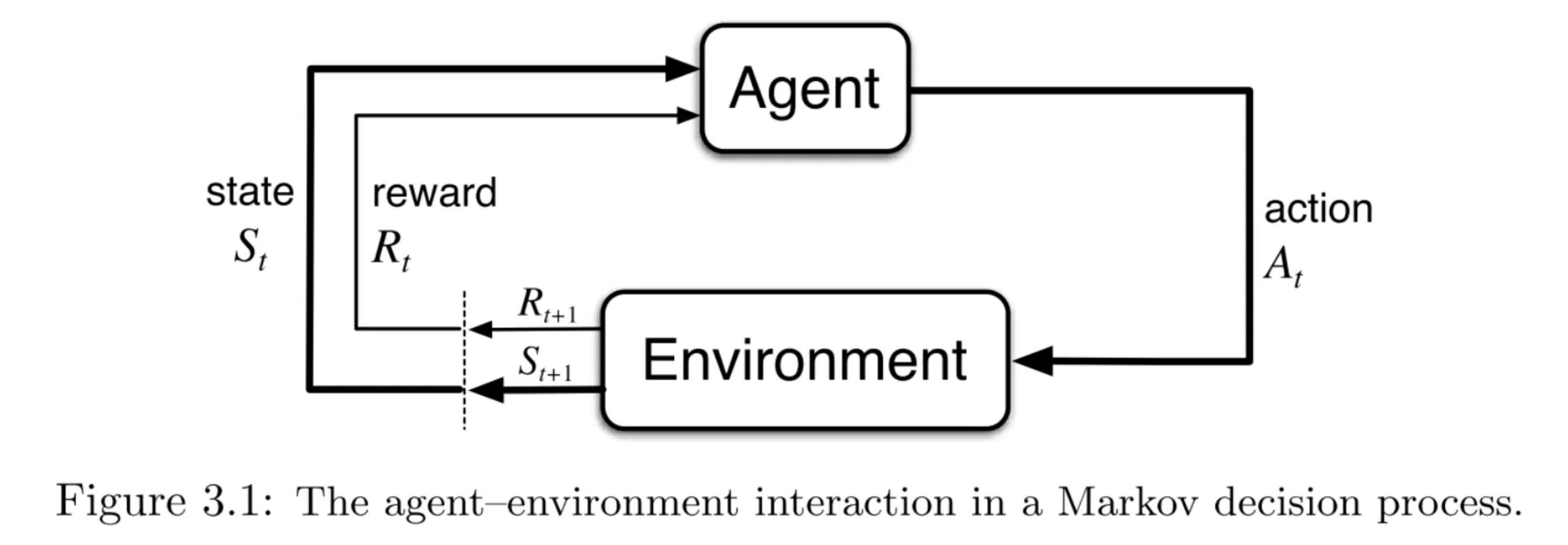
- In each step of time, the agent gets the current state (
S_t) as the input, takes an action (A_t, buy, hold, sell), and receives a reward (R_{t+1}) and the following state (S_{t+1}). The agent can now choose an action based on a policy (pi(S_t)).
The endgame is to find a policy that maximizes the cumulative reward sum (e.g., P&L) over some finite or infinite time.
We can visualize these concepts with this figure from Sutton & Barto:
Dynamic Programming (DP)
Dynamic programming can be used to calculate optimal policies on MDP, usually by discretizing the state and action spaces. Generalized policy iteration (GPI) is this process of letting policy-evaluation and policy-improvement processes interact through DP. Recall that we can improve a policy by giving a value function for that policy, with the following interaction:
- one process makes the value function consistent with the current policy (policy evaluation),
- and the other process makes the policy greedy for the current value function (policy improvement).
A possible issue, however, is the curse of dimensionality, i.e., when the number of states grows exponentially with the number of state variables in the learning space.
The DeFi Learning Agent
At a high-level, our learning agent must sense the state of the environment and then take actions that will change their state. In practical terms, our DeFi agent bot is developed and deployed through the stages below.
Data Engineering Infrastructure
Creating a data engineering infrastructure for extracting and cleansing historical blockchain data. For instance, we might want to retrieve ethereum logs, trace the mempool, or even extract data such as account balance and open limit orders. This part would also encompass feature selection, i.e., selecting the desired token pairs, DEX venues, and what data should be relevant.
Defining the Initial Policy
The next step is to model an initial policy. This can be done by extracting pre-labels from the training data (the historical data up to that point), running a supervised model training, and studying the features.
The action space could consist of three actions: buy, hold, and sell. The agent would initially have a deterministic amount of capital for each step.
However, the agent must learn how much money to invest in a continuous action space. In this case, we could introduce limit orders (with variables such as price and quantity) or cancel unmatched orders.
Optimizing the Policy and Parameters
The next stage is to optimize the agent’s policy, on which reward function could be represented by the net profit and loss (i.e., how much profit the bot makes over some time, with or without trading fees).
We could also examine the net profit the agent would earn if it closed all of its positions immediately. Moreover, adding real environmental restrictions is part of the optimization process.
The simulation could take into account order book network latencies, trading fees, amount of liquidity, etc. Making sure we separate validations and test sets is critical, since overfitting to historical data is a threat to the model.
Backtesting
The next step is backtesting this policy. At this point, we could consider optimizing the parameters by scrutinizing environmental factors: order book liquidity, fee structures, latencies, etc.
Paper-trading
Then, we would run paper trading with real-time new market data, analyzing metrics such as Sharpe ratio, maximum drawdown, and value at risk. Paper trading should prevent overfitting.
By learning a model of the environment and running careful rollouts, we could predict potential market reactions and other agents' reactions.
Live Trading
The last step is to go live with the deployment of the strategy and watch the live trading on a decentralized exchange.
Closing Thoughts
Here are a few questions for the anon to think about:
- What token pairs and dex market should our agent trade on?
- What are the heaviest features to be trained on and make predictions on?
- Can we discover hidden patterns from our feature extraction process?
- What should be the agent's target market, and what protocols and chains should we extract features from?
- What is the right state for the agent to trigger a trade? In high-performance trading, decisions are based on market nanosecond signals. Although our agent needs to be able to compete with this paradigm, neural nets are slow, up to minutes.
- Can we train an agent that can transit from bear to bull (and vice-versa)?